I always loved code optimization, because it’s easy to see the goal getting closer every iteration in an objective way, and it’s a hard challenge. You set a bar and then you start to sweat getting there. I decided I want to take latest distorm version and make it 2x faster in processing time. I find it deeply fascinating that the same mechanism with the same input/output can run much faster.
diStorm was designed to be fast from day one, and it was pretty much the case for many (~15) years when comparing diStorm to other disassemblers. Until recently (last few years) a new one claimed to be faster from some benchmarking I saw, although I’ve never validated it on my own. Amyway getting 2x faster wasn’t a small feat.
By designed-for-speed I mean:
1) single threaded!
2) diStorm doesn’t allocate memory at all (it takes buffers from the user)
3) doesn’t call any syscalls
4) it’s very simple in terms of calling-graph/functions
5) works with length’ed strings (as opposed to C strings)
6) parsing/decoding binary is fully separated from formatting the output strings
7) no initialization code is required (imagine distorm_init)
The test case consists of running the disasm tool (only commenting out the printf call) on some input file to decode it in 32 bits. Compiling the disasm itself with full-optimizations on and for x64 arch. My CPU is old: Intel SandyBridge Core i7-2600 @ 3.4 GHz. OS: Windows 10. The input is a dummy ~120MB file of code (c:\windows\system32\mrt.exe), which is good enough for my test. Starting above 5000 milisec and going down all the way to 2500 for a single thread!
The process of researching the code was done in two big steps (mind you, I had lotsa free time):
1) Research – Quick and dirty changes to the code, testing only once in a while for validness of output. Seeing progress fast. Eventually reaching goal (1 month almost full time).
2) Development – Starting coding all over again, verifying every new piece of code, adding more tests/coverage and making it production grade.
Code optimization falls under two categories, the way I see it, the obvious stuff that a profiler points to you and you can easily fix (normally not a great boost in performance, very specific touch). And the non-obvious stuff that can be refactored to get better performance but nothing will guide you the way to achieve it. And this is why I believe code optimization is really hard and more of an art form, as there’s no method directing you how to do it. Normally, one should make sure their code is tight in the algorithmic level and only then try to exhaust all the obvious fixes the profiler hints about. In reality, you go back and forth and after a while that you believe there’s nothing more to squeeze or re-write, you find new creative ways for the new code to work faster, and these are the big boosts.
The tools I used for my performance research were Intel vTune which is now free, and linux’ perf tool. Note that flamegraph wasn’t helping as the major code loop has 2 levels deep call stack. The advantage of using perf on linux is that you can query for the exact HW event, unlike the free version of vTune which queries all events altogether and their statistics are a bit more noisy thereof.
In the rest of this post I’m going to show a few of the best optimizations that had the biggest impact on performance (nonadjacent to research order):
- PGO – Profile Guided Optimization (feature is courtesy of Visual Studio). This one easily gets your code 10-20% faster and it’s ridiculous that I’ve never heard of it before, and neither many acquainted developers. The drawback is that it requires certain input to ‘learn’ how to prioritize/lay-out the code in order to make the code faster, in a disassembler’s case it’s pretty obvious anyway, so nothing to worry about. Basically, what it does is ordering basic-blocks and instructions to be in hot path (the instructions that mostly happen in a loop, for instance) and the cold paths (like error-handling that doesn’t happen often).
For example, for “if-else” ladder (or switch-case), it’s preferred that the more likely condition appear first. As to get to it you have less branches. This is one of the optimizations done automatically by PGO if it has sufficient data.
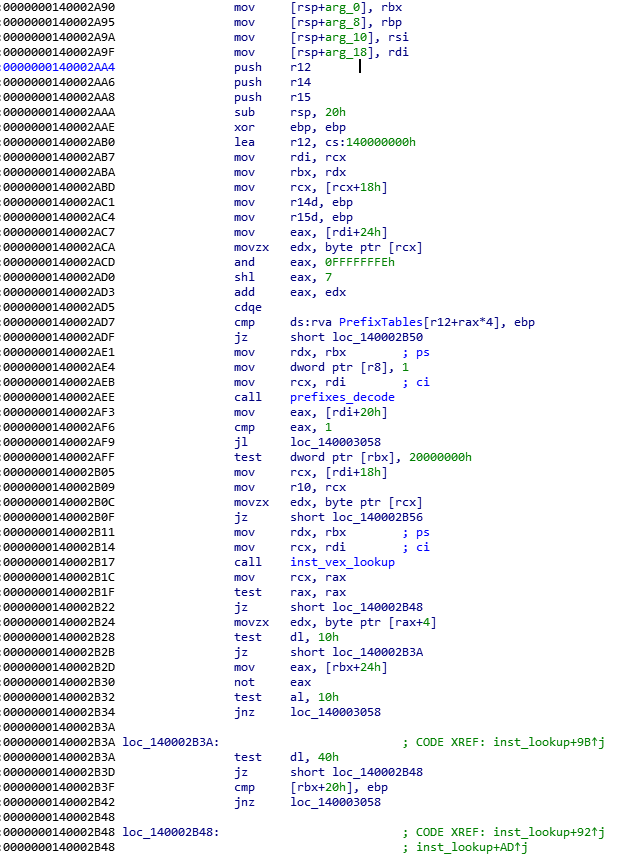
Now a stream of instructions can run consequently one after the other without branching and that’s amazing. See this picture of decode_inst disassembly of before-PGO here, and after-PGO here, notice the code layout and the latter function’s core is within one page.
Note that in order to use this feature it’s important to copy some DLL to the release directory, run the tool with the wanted input, and then re-compile the code with ‘optimizing for pgo’ in VS.
(exemplary path:
C:\Program Files (x86)\Microsoft Visual Studio\2019\Community\VC\Tools\MSVC\14.25.28610\bin\Hostx64\x64\pgort140.dll).
A tip: I created a compilation target that copies this file, compiles for PGO and runs the input file, and then compiles again with the created profile, this saved a lot of time. - Textual formatting a binary structure from _DInst structure to a textual structure (_DecodedInst) requires to do lots of string copyings of both mnemonic (ADD, MOV, XOR, …) and registers (AL, EAX, XMM0,…) and other constant string literals.
The main trick that boosted performance around 10% is to change the calls to memcpy with varied length to a fixed length.
Instead of callingmemcpy(output->mnemonicText, mnemonicsTable[mnemonicId].buffer, mnemonicsTable[mnemonicId].length);
We better do:memcpy(output->mnemonicText, mnemonicsTable[mnemonicId].buffer,16);
Now the compiler can fully omit the call to memcpy and just do a single instruction 16 bytes copy!
The reason it always copies 16 is because the longest mnemonic length is 16 of the instruction VAESKEYGENASSIST.
Caveats: 1) Adding padding in the table to avoid out of bounds is crucial. 2) All mnemonics are also zero terminated, so it’s okay to copy full 16 bytes even if the mnemonic is ‘MOV’, it’s really ‘MOV\0’, and yes it will copy other stuff in (but it’s ignored). 3) All final strings also have an integer length accompanying them!
For copying registers, making sure the table is as tight as possible and also copying a fixed length did the trick. Meaning that if there’s a table of registers in the form of:char registersTable[100][10] = {"eax", "ecx", ...};
It means that the access to each entry is a multiplication of 10, making it a power of 2 is easier for the compiler to optimize and it also saves a lot of memory space too. Biggest register string literal length is 5 (YMM15) and a null termination char is needed, so we can use 6, but better use 8 already. Then the memcpy of a register always copies 8 bytes no matter what.
Since x86 instructions have both string literal prefixes (rep, repnz, lock) and postfixes (eg CMPSD, CMPSW, CMPSB, etc), doing lookup tables also quickened stuff.
See code diff here (scroll down all the way).
Another trick that really helped, surprisingly, a lot is that I noticed string concatenation can work even faster. Note that all distorm strings are already length’ed, meaning it’s a structure with length and a buffer. And when a proprietary version of strcat is used it appends to the string and instead of searching the null termination it knows its length. But the surprise was that appending to the string with
memcpy(&str->buf[str->length], inputStr, inputLen);
was very slow according to just use a normal pointer, eg:
memcpy(str, inputStr, inputLen); str += inputLen;
So I had to change all distorm string functionality to work with a single pointer, and only at the end calculate the length and stuffing a null termination character.
Also note that at the same breadth I figured that distorm’s code has fixed sized string literals like the DWORD in ‘mov dword [eax], 8’, etc. So I forced distorm to use fixed sized memcpy’s too, which helped to compiler to eliminate them all and turn them into a simple qword-move. If you open distorm’s disasm code now you won’t see a single call to a memcpy function. This also saved a lot of time, 5-10%.
See relevant code diff here. - Another set of optimizations that shaved 10% further were to re-arrange if statements and code blocks that happen to run per instruction, but in reality they aren’t always needed.
The obvious guideline is that if the code does less stuff per iteration it’s likely to run faster.
Imagine the code checks something in the instruction. For example, do something for privileged instructions only. The first issue is that such instructions are input dependent (i.e out of our hands), the second one is that 99% instructions out of all instruction sets aren’t privileged to begin with. This means that the code should avoid doing checks for them, if possible. So I managed to omit a conditional statement…
One thing was to move things to that origin, for example, if something was dependent on the optional operand of an instruction, and the test was done in the per-instruction code, obviously if we move the test to the origin (inside the operand parser), then things will run faster.
Another was that some extra features were done naively (distorm tracks all used/unused prefixes and generates relevant masks), so optimizing these boosted the performance too. Sometimes a profiler makes things clear where it’s worth to optimize stuff.
Sometimes it’s better to do a=x; if (y) a=z; instead of if (y) a=z; else a=x; which also might help for performance.
Assuming happy flow wins and optimize for that can also drastically help. Sometimes you can check for faults at the very end of the step instead of every sub step (if the mechanism allows to do so).
Taking into account data cache locality (which I haven’t ever before dealt with till now). If you touch some memory, be sure to exhaust that piece of data until you don’t need it anymore. Instead of re-visiting that memory again and again. So re-ordering code accordingly saves a lot of time loading stuff to the cache.
Trying to re-order the multiple conditions in an if statement might help, perhaps PGO does it on its own. But always start with the less likely condition to happen, so you quit checking further and sooner.
Another example is that sometimes the code used to deref some pointer and not always use that value, so postponing the deref only to the site where it’s really needed, can also boost performance.
Many small things like that helped to increase performance of the decode_inst function, you can check out the diff here, but it’s spanned across a few commits. - Optimizing operands extraction also saved around 10%. For example some operands need to read further information from the binary stream and reading from the stream can vary with size of 1, 2, 4, 8 bytes. The original function is something like this:
int read_stream(const char* codeBuf, unsigned size, uint64_t* out)
{
switch (size) {
case 1: *out = *codeBuf; break;
case 2: *out = *(uint16_t*)codeBuf; break;
...
}
}
Now given the compiler knows the sizes of how much to read from the stream because all callers to read_stream specify ‘size’ as a constant, then it can really optimize the whole switch statement and just read what’s need from the stream, no biggy.
The problem is that the function wasn’t inlined at all, and thus each stream reading took a lot of time just because of the branches. Making this function inline saved around 5% by itself, for free! :)
Another issue was that a few things always happened in the beginning or ending of an operand extraction function that could be done lazily or postponed to the exact right moment, like described in the previous point, and the also saved significant time.
The operand_extract function originally took around 11 argument, trying to reduce these and work with less argument is normally better. Some operands were calculated again and again (like the operands array index, &ops[index]) which sometimes is already calculated once, so try to pass it along instead, can save also some time. It sounds like small stuff, and it is, but eventually when you stop coding naively and start to see this stuff in the profiler and also by looking at the code, it adds to a lot.
Since there are some 100 internal types of operands in distorm, they were classified to a few categories. Now the original code did something like: switch (type) case 1, case 2, case… and then another switch (type) case 10, case 11, case 12… and then yet another switch (type) case 20, case 21, case 22, and so on. Meaning that the case of 22 will get evaluated in two switch tables even though it surely gets to run code only in the third switch case. This can generate branch prediction noise (as these switch statements eventually become a jump table) and waste time also because it’s not hitting a target basic block, just going through to the next basic block. So I chose to add a corresponding range checks before each switch statement to spare the wasteful look ups. Alternatively it was possible to coalesce all switch cases under a single switch, but I didn’t like that form of code in my case. - distorm has eventually two APIs, one for textual based disassembling and another for actual binary structure output, internally this functionality runs first, and then it formats the binary to text.
But since the prototype of the functions take different input and output structure it changes how the core engine works with the output memory.
In one of the main loops of converting the binary structure into textual output, distorm used to copy the binary structure (from uer’s memory) to a temporary on-stack memory, and then feed it as input into the formatting function, so eventually the user’s memory is the output one. Eventually I decided to eliminate the temporary buffer and make sure the formatting functionality can work with the same input/output buffer in-place!
Well better see it in pseudo code:for (i = 0; i < instsCount; i++) {
// insts[i] is a binary form of the instruction
memcpy(&tmp, insts[i], sizeof inst);
format_inst(&tmp, insts[i]); // in: tmp, out: insts[i]
// Now insts[i] is a different struct with textual output
}
This in-place memory trick saved around ~3% and it required to refactor the formatting function so same memory fields had to be touched carefully, so we don’t override with text some binary fields that we need yet to convert…
See code diff here. - distorm has some extra features that require extra work CPU time to get them done. One of them is a very simple feature to return the relevant eflags of each decoded instruction (inside _DInst it’s modified, undefined and tested eflags masks). For example a JZ instruction takes ZF as input. ADD instruction writes to a few flags such as: AF, ZF, PF, OF, CF, etc. And some instructions even change some flags into an undefined state.
This feature works all the time, even in a textual mode of the disassembler, like in most cases, and wastes time. So I turned this code into a feature that the user can select if they want to opt-in, and this saved ~3%.
Moral of the story: don’t calculate stuff nobody uses!
Note that what takes time in this is copying the compacted eflags to the extracted eflags compatible masks in the final output buffer…
See code diff here, nothing interesting.
{kind=link}
{kind=link}
There are many more tricks, but these are the most performance impact.
Eventually this research taught me a lot about the modern processors pipeline, which is fascinating and worth to read about it from a few links.
Sometimes it was frustrating move one c code line from one place to another, which at times made things faster and sometimes slower. Sometimes eliminating a whole line made things slower, really. And some other times putting a new line and even an access to a memory address made things faster in the right place. Modern pipelines are somewhat voodoo, and be careful not to optimize for a specific one, there was some point that I decided to keep the code in readable C and playing with single lines is not a great idea, unless you can reason with it and a profiler yells at you to change it.
Cache was always an undervalued thing for me, even though I’ve been coding for over 2 decades now, I always took it for granted, but in reality once you understand the cache, you can get your code faster. And many naive things I did (which I didn’t consider myself a naive coder in terms of speed), were also bad. So in this exercise I learned a lot and tried to share some useful and practical points with you and less about the research itself. Hence I avoided talking about the processor itself (for instance, icache vs. DSB) and the tiresome process of benchmarking instructions, branches and uops, etc.
I guess looking at the code of the original version and the final version and comparing them can teach one a lot, in files such as decoder.c, distorm.c, operands.c, prefix.c and textdefs.c.
Here’s the log I kept of the second phase, (headers: timestamp, measurement time in MS, comment):
4:42 PM 4/21/2020 5170 BASELINE # MRT.exe (120MB) decoded in 32 bits. disasm compiled for x64.
5:35 PM 4/21/2020 4964 DF_FILL_FLAGS feature.
11:02 PM 4/21/2020 4832 In-place formatting.
11:58 PM 4/21/2020 4482 Fixed size register & mnemonic copying.
8:58 AM 4/22/2020 4393 str_hex optimized.
9:35 AM 4/22/2020 4386 textdefs.c cosmetics.
5:01 PM 4/22/2020 4130 wstring and textdefs optimizations.
5:00 PM 4/23/2020 3969 format optimizations.
5:02 PM 4/23/2020 3562 PGO enabled for mrt.exe.
4:56 PM 4/25/2020 3300 prefixes and decode_internal optimizations.
10:12 AM 4/26/2020 2890 optimized inst_decode.
3:33 PM 5/4/2020 2690 prefixes and operands optimizations.
11:44 PM 5/7/2020 2610 more prefixes and operands optimizations.
9:53 AM 5/14/2020 2500 prefixes, operands, decoder optimizations.
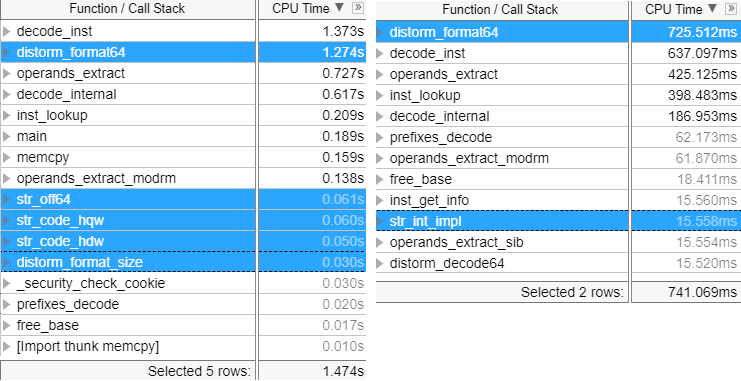
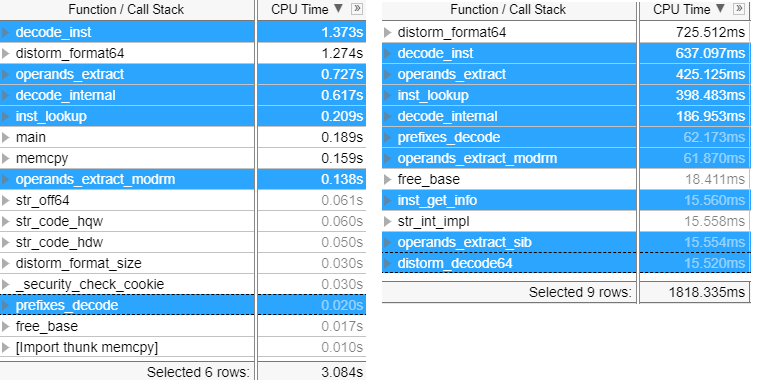
And these are vTune profiler showing the functions and timings (not fully accurate to my original tests TBH) for the formatting functionality (down from 1474 to 741 MS – 1.98X ) and the decoding functionality (down from 3084 to 1818 – 1.7X), you will see less symbols in the optimized functionality thanks to in-lining.
{kind=link}
{kind=link}
Future challenges for distorm – there are still 2 functions that drive me nuts that I managed to optimize a lot but are still slow and deserve probably tons of attention: a proprietary version of itoa for converting integers to hex ascii numbers (str_int_impl), and converting binary bytes to hex ascii (str_hex). And optimization there is super helpful.
Some useful links:
- Introduction to modern pipeline and CPU-bound optimizations by ScyllaDB
- An Introduction to the Cache Hit and Miss Performance Monitoring Events
- Ahmad Yasin – A Top-Down Method for Performance Analysis and Counters Architecture
- Sandy Bridge (client) – Microarchitectures – Intel
- Avoiding instruction cache misses
- Avoiding the Cost of Branch Misprediction
- Top-down Microarchitecture Analysis Method Overview